Tensorflow 공식 사이트의 추천공부코스를 따라가다보면 처음 나오는 강의이다. Udacity라는 플랫폼을 통해서 Tensorflow를 이둉해서 딥러닝에 대해서 배운다.
Colab을 사용하며 매우매우매우 기본적인 파이썬(입력 포맷)에 대해서 배우고 강의가 시작된다. 기본적인 예제는 이미 제공되기 때문에 따라하는 것은 어렵지 않다. 총 11강
1강 : Tensorflow를 통해서 deep learning에 대해서 배우고 tensorflow는 매우 좋다고 설명한다.
2강: Tnesorflow를 이용해서 섭씨와 화씨 데이터를 가지고 예측알고리즘을 만드는 것을 실습한다. single dense 모델을 이용하여 알고리즘을 학습시킨다.
Regression, output = number, loss function = mean squared error
Artificial Intelligence: A field of computer science that aims to make computers achieve human-style intelligence. There are many approaches to reaching this goal, including machine learning and deep learning.
Machine Learning: A set of related techniques in which computers are trained to perform a particular task rather than by explicitly programming them.
Neural Network: A construct in Machine Learning inspired by the network of neurons (nerve cells) in the biological brain.
Neural networks are a fundamental part of deep learning and will be covered in this course.
Deep Learning: A subfield of machine learning that uses multi-layered neural networks. Often, “machine learning” and “deep learning” are used interchangeably.
코딩의 소스코드 자체는 어렵지 않으나 머신러닝 학습의 개념( 데이터 -> 학습 -> 결과 -> 비교)이 익숙치 않으면 " 아... 음.. 그렇군..." 하고 넘어가게 된다. 이후에 좀 더 자세하게 설명해주신다고 한다. (수학적 이해가 되어야 이런 원리로 작동하는구나 알고리즘의 원리에 대해서 알고 사용할수 있을 것 같다. 아니면 그냥 평범한 한번 딥러닝 한번 사용해봤어요.로 끝날것 같다)
==== 1시간 20분 ====
3강: 딥러닝은 반복작업을 대체하는 곳에서 사용될 것이다.
input 데이터를 feature 이라하고 output 데이터를 label이라고 한다.
Fashion MNIST를 이용하여 이미지를 분류하기. Relu activation function을 이용한다.
Classification, output= set of numbers that represent probabilites(sum =1), loss=function : sparse_categorical_crossentropy. last layer activation function = softmax, 2D 이미지를 1D 벡터로 바꾸는 작업 = flattening.
ReLU
https://www.kaggle.com/dansbecker/rectified-linear-units-relu-in-deep-learning
Rectified Linear Units (ReLU) in Deep Learning
Explore and run machine learning code with Kaggle Notebooks | Using data from no data sources
www.kaggle.com
l03c01_classifying_images_of_clothing.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
이미지를 어떻게 트레이닝 시키고 예측을 어떤식으로 하는지 fashion MNIST 데이터를 이용하여 보여주고 있다. 기본적인 개념에 대해서 설명하고 있지만 짧은시간에 완전히 이해시키기엔 어려움이 있는 것 같다. 강의를 듣는중에 모든것을 완전히 이해하는 것 보다 강의를 쭉 다 보고 이론적인 개념에 대해서 찾아보면서 여러번 노출시키는 것이 더 쉽게 이해할 수 있을 것 같다.
==== 30분 ====
4강: Convolutional neural network.
CNN 은 이미지, 비디오등을 분석하는 곳에 사용할 수 있다.
1989년 개발되었다. 알고리즘이 응용분야를 확장시킨것이 아니라 데이터가 응용분야를 확장시켰다.
CNN은 이미지를 clacificassion 하고 symbol를 찾는데 매우 효과적인 알고리즘이다.
두가지 중요한 개념 = convolution 과 Max pooling.
1. kernel or filter across different areas of the input image. 인풋 이미지의 픽셀과 커널의 값을 곱해서 새로운 covolution된 값을 구한다. 인풋이미지의 edge에서는 kernel에 포함되지 않는 부분을 무시하거나 0으로 만들어서 convolution 값을 계산한다.
2. max pooling is just the process of reducing the size of an input image by summarizing regions. 먼저, 그리드(pool size)의 크기를 정한다. 그리드 안에서 가장 큰 값이 새로운 이미지의 대표값이 된다. 두번째, stride의 크기를 정한다. stride는 그리드가 covolution 이미지에서 움직이는 크기를 정의한다. (the number of pixels to slide the window across the image). 두 과정을 거치게되면 이미지의 크기가 작아진다.(we'v down sampled the original image)
Here are some of terms that were introduced in this lesson:
CNNs: Convolutional neural network. That is, a network which has at least one convolutional layer. A typical CNN also includes other types of layers, such as pooling layers and dense layers.
Convolution: The process of applying a kernel (filter) to an image
Kernel / filter: A matrix which is smaller than the input, used to transform the input into chunks
Padding: Adding pixels of some value, usually 0, around the input image
Pooling The process of reducing the size of an image through downsampling.There are several types of pooling layers. For example, average pooling converts many values into a single value by taking the average. However, maxpooling is the most common.
Maxpooling: A pooling process in which many values are converted into a single value by taking the maximum value from among them.
Stride: the number of pixels to slide the kernel (filter) across the image.
Downsampling: The act of reducing the size of an image
CNN이 dense layer보다 더 좋은 정확도를 보여준다. 하지만, 너무 많은 정보를 입력하면 반복해서 기억하기 때문에 overfiting이 되어 정확도가 떨어진다. 다음강의에서 overfitting을 비하는 방법에 대해서 배운다.
l04c01_image_classification_with_cnns.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
A Comprehensive Guide to Convolutional Neural Networks — the ELI5 way
Artificial Intelligence has been witnessing a monumental growth in bridging the gap between the capabilities of humans and machines…
towardsdatascience.com
==== 30분 ====
5강: Going Further with CNNs
Udacity cofounder(Sabastian)와의 인터뷰: 딥러닝에서 90% 는 데이터를 cleaning 하는 작업이다. 굉장히 crooked(비뚤어진, 부정직한, 짜증나는 ) 작업이다.
CNN의 장점 = color image와 고화질이미지를 분석할 수 있다.
Dog와 Cat dataset (마이크로소프트 세라(?) 데이터) 를 활용하여 고화질 이미지 분석하기
- 서로 다른 사이즈 이미지
- 컬리이미지
이전강의에서는 28x28 크기의 이미지를 곱해서 flatening했다. 크기가 다른 고화질 이미지를 작은 사이즈로 resize한다음 flattening 해야한다.
컬러이미지는 이미지에 높이 x 폭 x 그리고 컬러채널 3가지(RGB)에 대한 정보를 입력해야한다.
covolution을 할때도 RGB의 3가지 색이 있기 때문에 filter 에도 3가지 채널이 있다. 각 채널의 이미지와 필터의 covolution 값을 구한후 하나의 값으로 더한다. 그리고 커스텀벨류를 더 한다(보통 1) 3D covolutional filter의 갯수를 여러개 사용하면 더 많은 3D covolutional image를 얻을 수 있다.
Max pooling은 그리드의 크기와 stride크기를 정한뒤 최대값을 찾아 각각의 3D convoluted output에서 새로운 이미지를 만든다.
binary classification 문제에 대해서 softmax activation function 말고 sigmoid activation function 또한 유용하게 사용된다.
Training set에서 over fitting 되는 것을 확인하기 위해 validation set을 만들어서 clean한 데이터에서 정확도를 파악한다. Training에서 정확도가 높고 validation 에서 정확도가 떨어지면 overfitting되었다는 것을 나타낸다. to aviod the overfitting look at the plot of the training and validation loss as a function of epochs. 어떤 epoch (에픽스)지점에서 validation loss가 다시 늘어나고 training loss는 계속해서 줄어든다.. 일정 epoch를 넘어서면 deep learning 알고리즘이 training의 결과값을 기억하기 시작하면서 overfitting 된다.
CNN에서 object detection 을 향상시키는 방법 : image augmentation, 기존의 이미지를 회전, 반전, 확대, 축소함으로써 새로운 형태의 이미지를 만들어서 training 시키다. 더 다양한 이미지를 가지고 training하기 때문에 성능이 올라간다.
overfitting을 피하기 위해 dropout 방법을 사용할 수도 있다. 특정, neuron의 가중치(weight)이 클경우 전체분석 과정에서 영향이 커서 다른 뉴런의 특성이 잘 적용되지 않을 수 있다. 그렇기 때문에 training과정에서 몇가지 뉴런을 dropout(turn off) 함으로써 각각의 특성이 결과에 어떤 영향을 끼치는지 확인 할 수 있다.
Memorizing is not learning! — 6 tricks to prevent overfitting in machine learning. | Hacker Noon
Memorizing is not learning! — 6 tricks to prevent overfitting in machine learning. Introduction Overfitting may be the most frustrating issue of Machine Learning. In this article, we’re going to see what it is, how to spot it, and most importantly how
hackernoon.com
l05c02_dogs_vs_cats_with_augmentation.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
==== 90분 ====
6강 transfer learning.
다른 연구자들이 이미 세팅해놓은 모델을 output layer 값만 변경해서 우리의 모델에 적용시킬 수 있다.
pre-trained 된 모델의 설정값을 유지하는 것을 Freezing Parameters 라고한다.
tensorflow hub에서 pretrained models을 공유하고 있다. (tensorflow에서의 모델은 마지막 layer가 제거된 상태로 제공한다)
Tensorflow hub는 transfer learning을 위한 pre-trained model을 제공하는 라이브러리이다.
l06c01_tensorflow_hub_and_transfer_learning.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
Understanding your Convolution network with Visualizations
The field of Computer Vision has seen tremendous advancements since Convolution Neural Networks have come into being. The incredible speed…
towardsdatascience.com
연습
l06c02_exercise_flowers_with_transfer_learning.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
답지
l06c03_exercise_flowers_with_transfer_learning_solution.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
Transfer Learning: A technique that reuses a model that was created by machine learning experts and that has already been trained on a large dataset. When performing transfer learning we must always change the last layer of the pre-trained model so that it has the same number of classes that we have in the dataset we are working with.
Freezing Parameters: Setting the variables of a pre-trained model to non-trainable. By freezing the parameters, we will ensure that only the variables of the last classification layer get trained, while the variables from the other layers of the pre-trained model are kept the same.
MobileNet: A state-of-the-art convolutional neural network developed by Google that uses a very efficient neural network architecture that minimizes the amount of memory and computational resources needed, while maintaining a high level of accuracy. MobileNet is ideal for mobile devices that have limited memory and computational resources.
transfer learning에 대한 개념을 알아보았다. 기술적으로 코딩하는 그렇구나하고 보고 자료만 저장하였다. 구글 MobileNet 모델을 이미지 분석하는데 유용하게 사용할 수 있을 것 같다.
==== 30분 ====
7강 Saving and Loading Models
텐서플로우를 통해 학습시긴 모델을 저장하여 다른 플렛폼에 적용시킬 수 있다.
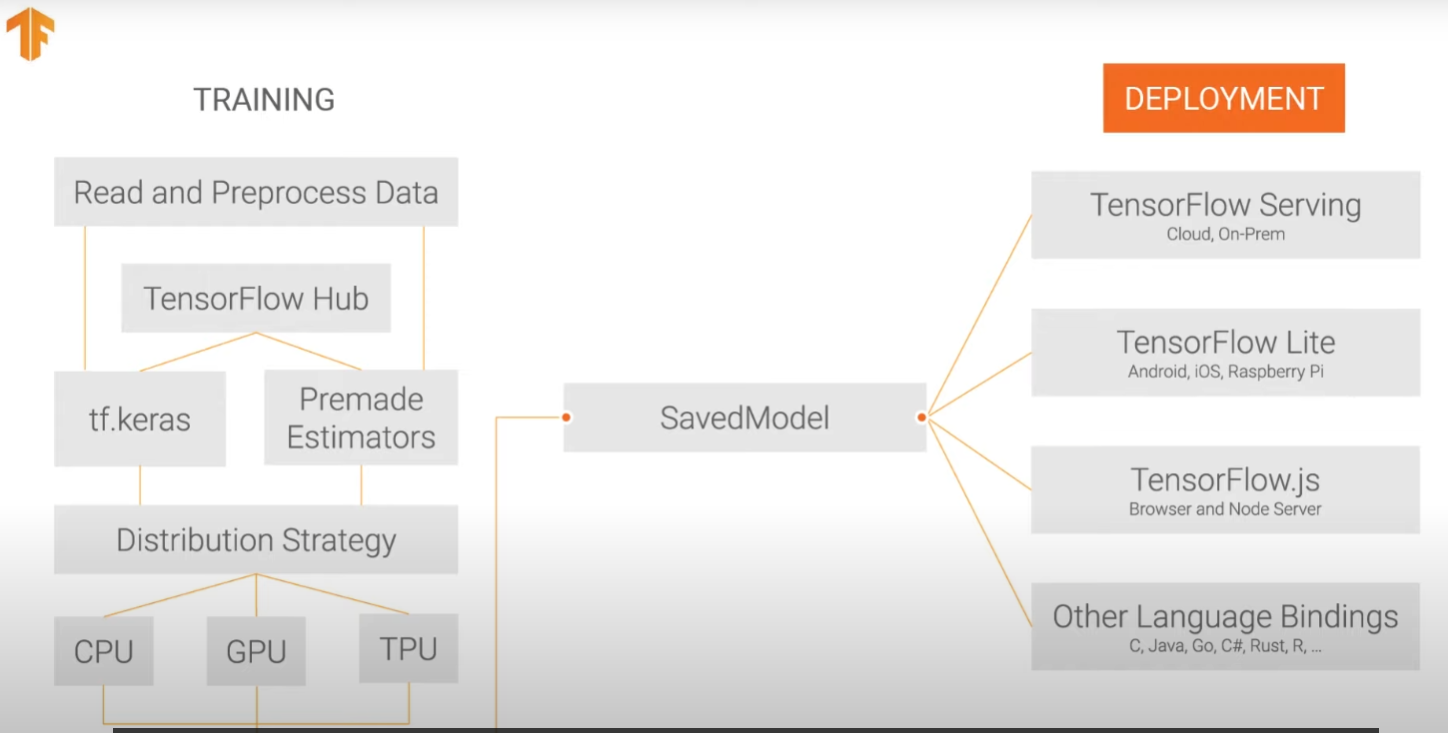
텐서플러우 설치 - 모델 불러오기 - 데이터불러오기 - 훈련과 검증으로 나누기 - 모델에 맞는 이미지 해상도 설정하기 - 모델에 데이터 넣기 - 전이모델 적용(MobilNet) - 파라미터 고정 - output layer 설정 - 컴파일하기 - 모델 트레이닝하기 - 결과 확인하기 - 모델 저장하기 HDF5 file .h5
l07c01_saving_and_loading_models.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
데이터를 훈련시킨다음 모델을 저장할 수 있으면 스마트폰과 같은 휴대용기기에서도 즉각적으로 딥러닝을 사용할 수 있다.
==== 20분 ====
10시 10분 12까지 11시 23분, 10시 - 10:30 14강
8강 Time Series Forecasting (시계열 예측) (시간연속예측)
시간이 변함에 따라 변하는 값을 예측하는 것은 매우 유용하다.
일반적인패턴: Trend(증가 혹은 감소), seasonality(특정 주기를 가진값), white noise (일정한 무작위값)
l08c01_common_patterns.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
예측(Forecasting)
Naive forecasting ( 순진한, 단순한 예측) : 최근 데이터를 수정없이 예측데이터로 활용한 예측
Roll-Forward Partitioning - 단점 시간을 많이 소비함,
naive forecasting으로 예측된 값( mean absolute error) 은 예측판단의 기준이 된다(baseline)
mean absolute error 은 에러값이 측정결과에 큰영향을 미치지 않을때 사용할 수 있고
mean square error 은 에러값이 결과에 영향을 미쳐 중요할때 의미있게 관찰할 수 있다.
l08c02_naive_forecasting.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
Moving avaerage (이동평균) 을 이용하면 seasonality를 가진 데이터에서는 특정값을 예측하기 어렵다. 또한, Moving average 를 이용하면 데이터가 갑자기 변할때 딜레이가 생겨서 예측값이 떨어지게 된다.원래 데이터에서 seasonality를 제거한 후 moving average를 이용해서 예측할 수 있다.
l08c03_moving_average.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
데이터를 머신러닝이 학습하기 위한 데이터로 바꾸는방법. 텐서플로에서 제공하는 tf.data라는 함수를 이용하면 간단하게 만들 수 있다. 개념: 연속적인 데이터를 작은 크기로 잘라서 텐서플로가 학습할수 있는 텐서로 만든다음 부분부분 학습시킨다.
l08c04_time_windows.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
학습을 시키는 과정에서 최적화되는 hidden layer, reLu의 갯수를 정해야한다. loss가 증가하면 epoch를 중간에 멈추도록 할 수 있다. 여러가지 error를 optimize하는 방법들이 있다.
keras를 이용해서 머신러닝을 진행하였다.
l08c05_forecasting_with_machine_learning.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
Recurrent Neural Network (RNN) (이건 뭔가 어렵다 ... ㅠ 14강 )
Recurrent layer 은 하나의 memory cell을 가진다. 반복되서 계산될때 output이 새로운 계산에 사용된다. (RNN은 정보를 기억momory 할 수 있다) 이전 데이터를 기억할수 있어서 성능이 좋아질 수 있지만 트레이닝 시키기 어렵다. 10H
11강 Introduction to TensorFlow Lite
텐서플로 라이트는 디바이스에서 사용할 수 있도록 만든 제품이다.
https://www.udacity.com/course/intro-to-tensorflow-lite--ud190
https://www.udacity.com/course/intro-to-tensorflow-lite--ud190
With TensorFlow Lite, the Google TensorFlow team has introduced the next evolution of the TensorFlow Framework, specifically designed to enable machine learning at low latency on mobile and embedded devices. This course was created as a practical approach
www.udacity.com
'프로그래밍 > 파이썬' 카테고리의 다른 글
| 파이썬 자주할 수 있는 실수 (0) | 2021.06.02 |
|---|---|
| [tensorFlow] TensorFlow in Google colaboratory (0) | 2021.06.02 |
| [패스트캠퍼스] 파이썬을 활용한 이커머스 분석 올인원 패키지 후기 (0) | 2021.05.30 |
| 파이썬 기초 [점프 투 파이썬 - 어떻게 시작해야할까, 정규표현식] (0) | 2021.05.28 |
| 파이썬 기초 [점프 투 파이썬 - 날개달기] (0) | 2021.05.28 |